
The main objective of the Awetí Language Documentation Project is the comprehensive documentation of the language spoken by the Awetí, an indigenous tribe of just over a hundred people living in the Xingú headwater area of central Brazil. The documentation results in a comprehensive multimedia corpus included in the DOBES archive. This corpus is suitable as a basis for further research on the language and culture of the Awetí even if and when the language and culture become extinct. The Awetí Project closely co-operated with two other DOBES projects on languages in the area (Trumai and Kuikuro / Upper Xinguan Karib): all these languages are genetically unrelated. Co-operation was to ensure, among other things, the creation of analogous corpora for the three languages.

Sebastian Drude with Awetí men in the central hut
The central part of the Awetí database is a corpus of texts of different major text genres that have been recorded, transcribed and translated at least into Portuguese and usually into English, as a minimal form of text processing. This minimal annotation is provided with time linking in the ELAN annotation format and can be accessed via the web.

Awetí house in construction
The database also includes various types of multimedia material documenting different areas of the Awetí culture; this material is as a rule closely connected with the topics dealt with in the texts of the text corpus. Finally, a lexical databank is under construction, as exhaustive as possible, whose entries are partially extracted from the texts and partially result from systematic elicitation.

Tawarawaná festival, the sitting singer is a main Awetí story-teller and ritual specialist
The Awetí are taking an active part in the documentation. They not only receive and support the members of the Project team each year for several weeks in their village for field work, but also more and more take over the responsibility of transcribing and, partly, translating texts. During the project they learned to make audio and video recordings and to make basic use of a laptop. Thus they can continue the documentation of their language and especially their culture on their own. Basic equipment has been provided as part of the project.

A young Awetí documenting the Tawarawana festival

An Awetí co-worker with the community laptop
The Awetí have become aware of the fact that, given the small number of speakers and rapid change in the conditions for maintaining their culture, both the Awetí language and the Awetí culture are threatened with extinction. The older generation is saddened by the fact that little time is spent by the young people on learning and continuing the rich tradition in oral literature. Therefore documenting this literary tradition has been an important part of the project.

Sebastian Drude with the father of the chief and main informant, taping narratives
Generally, the documentation of the Awetí language has relevance to cultural documentation as a major criterion in the selection of texts. However, a subpart of the text corpus will receive detailed linguistic annotation so as to provide a basis also for further linguistic work on the language.
The Awetí language was first studied in the late 1960s and early 1970s by the Brazilian linguist Ruth Monserrat, who, however, eventually discontinued her research, with few results published. Sebastian Drude, the principal researcher in the current documentation project, resumed field work on the Awetí language in 1998. Since 2001 he is being assisted by Sabine Reiter who started as a freelance linguist and became a regular member of the research-team in 2002. Several members of the Awetí community visited Belém in 2001 and 2002 to work with the researchers at the transcription and translation of the collected data in the Museu Paraense Emilio Goeldi.
Members of the Awetí project developed Advanced Glossing (Lieb/Drude 2000), a general model for linguistic annotation at all structural levels: phonetic/phonological including lexical intonation and prosody, individual glossings for words (syntax) and morphs (morphology) including lexial and unit categories, constituent and relational structures and semantics. This model is partially being applied for more detailed annotation, using the Toolbox computer program (Drude 2002).
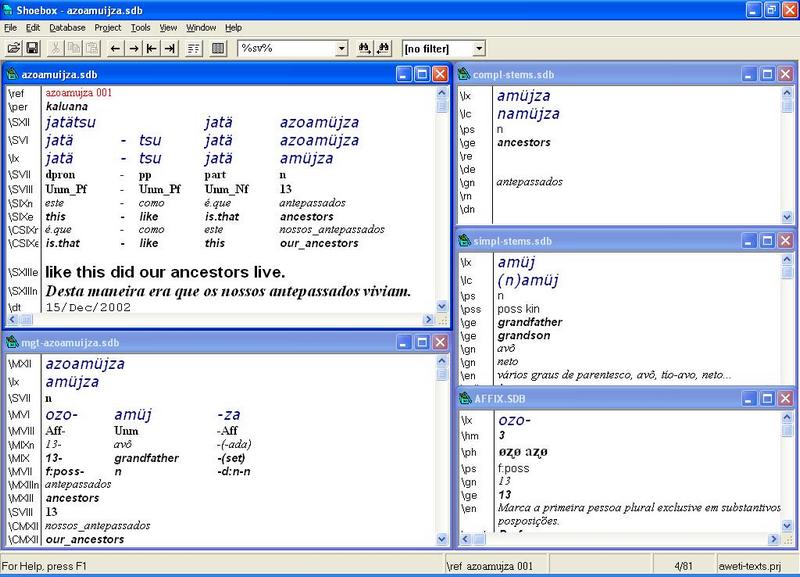
Shoebox sample demonstrating the configuration with a syntactic glossing (top left), a morphological glossing (bottom left) and relevant entries in the lexical databases for complex words, simple words/stems and affixes (right, top-down)
For a more complete description of the project in a rather colloquial manner (in German), see Drude 2001. The methodology is described in detail in Drude 2002.